-
") Ribary, Marton Dr (School of Law) authoredRibary, Marton Dr (School of Law) authored
Ribary, Marton Dr (School of Law) authoredRibary, Marton Dr (School of Law) authored
"SQL" - Relational database
SQLite database built with sqlite3 on the command line and the sqlite3 Python package.
1. Create database: digest.db
D_sql_create_db.py > digest_skeleton.db
The Python script imports sqlite3 and its Error function and creates an empty database stored in the sql folder of the repository.
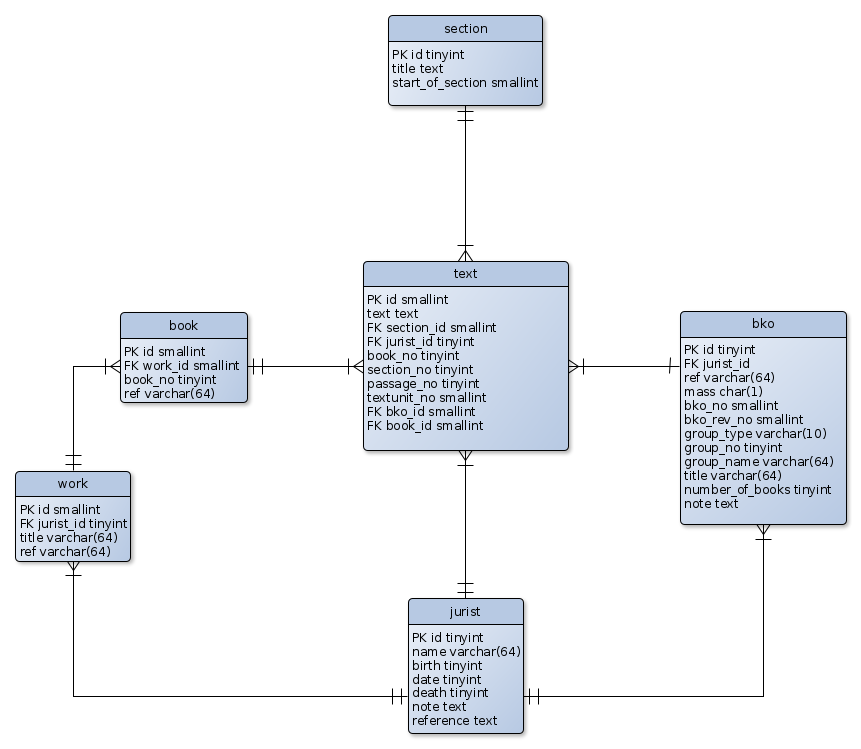
Manual schema > D_sql.graphml
The core structure of the digest database is drafted in the yEd graph editor and stored in the images folder of the repository. It includes the name and datatype of the fields in the various tables and notes their primary (PK) and foreign keys (FK). The graph's edges uses the arrow symbols to indicate one-and-only-one to many-or-one relations between the tables.
D_sql_create_tables.py > digest_skeleton.db
The Python script imports sqlite3 and its Error function. It defines a Connection object for accessing digest_skeleton.db and a cursor object to create tables in it. The file's main function defines six tables with their primary keys, fields and datatypes as well as their foreign key restrictions which create connections between tables. The structure follows the structure drafted in the D_sql graph above.
Running the file creates the tables which are checked by looking at digest.db in the command line by sqlite3 with > .tables. Fields and datatypes are checked by the following sequence of commands: > .header on > .mode column > pragma table_info('text');.
D_sql_load_data.py > digest.db
A copy of digest_skeleton.db is made in the same directory. This digest.db file will be used to populate the database with information from the flat files created in the "Ddf" stage of the project. The script establishes a connection with the database by creating a Connection object. Six create_ functions are defined for each of the six empty tables in digest.db: (1) create_jurist, (2) create_work, (3) create_book, (4) create_bko, (5) create_section, and (6) create_text. These functions create a Cursor object with a method of the Connection object and include a SQL statement which enters one row into the table with values matching the table's column labels. As the struture of flat files do not match the structure of the tables, the script creates some temporary dataframes collecting information in the right order, right format and adhering to the restrictions (keys, data types restrictions etc.) of the SQL schema. The script's main function populates the tables with the create_ functions by looping over the rows in the relevant flat files. The script ends with the command of running the main function. No error message is received which means that the loaded data adheres to the restrictions. The populated digest.db database file is inspected with the sqlite3 command line application as well as in the graphical interface of DB Browser for SQLite.
2. Instructions for using digest.db
The digest.db database can be used for generating advanced analytical insights about Roman law as represented by the Digest. The database can be queried with standard SQL statements in three types of SQLite interfaces listed below.
Command line interface (CLI) - sqlite3
Instructions for installation can be accessed on sqlite.org.
Graphical user interface (GUI) - DB Browser for SQLite
Instructions for installation and use can be accessed on sqlitebrowser.org.
Online application - SQLite online
Instructions for installation and use can be accessed on sqliteonline.com.
The websites of the listed applications include instructions for querying databases with SQL statements. All interfaces allow exporting results into flat files such as csv. The exported csv could be opened in a regular spreadsheet application such as Excel or libreoffice-calc. The csv files could also be loaded as pandas dataframes into a Python code for further processing.
3. Sample SQL queries
There are some sample queries in the SQL_queries.txt file to assist users unfamiliar with the SQL query language. The queries are all ready to be copied and pasted as a multi-line SQL query into the interface of your choice. The queries can be customised by replacing the relevant values. Names of tables and their columns are fixed, but all other values can be customised. Please play around.
Take the following SQL query from SQL_queries.txt.
-- Count the number of text units for each jurists
SELECT j.name, j.date,
COUNT(t.jurist_id) as number_of_textunits,
CASE
WHEN j.date < 0 THEN 'E'
WHEN j.date < 190 THEN 'C-'
WHEN j.date < 240 THEN 'C+'
ELSE 'P'
END AS era
FROM text as t
LEFT JOIN jurist as j
ON t.jurist_id=j.id
GROUP BY t.jurist_id
ORDER BY j.date;This query sorts the jurists of the Digest into so-called eras: "early and pre-classical" ('E'), "early classical" ('C-'), "late classical" ('C+'), and "post-classical" ('P'). The date column in the jurist table includes the date when the jurist was most active.1 For the purpose of this periodisation, the query takes the year 0, the year 190 and the year 240 as the boundaries of the eras. Additionally, the query counts the number of text units authored by a partcular jurists by linking the jurist and the text table on a common key (jurist_id). The output is ordered by date where jurists, their eras and the number of text units they have in the Digest are listed in SQL table ready to be exported.
The user may define different boundaries, or name the eras differently by replacing the numeric values and the encoding of eras stated in single quotation marks. Less or more eras can be defined by removing a WHEN line or adding more to the query as appropriate.
Help with SQL queries
Please leave a comment or send an email, if you would like to request a sample SQL query for your research, or if you need help adusting one of the existing queries.
4. Future steps
The current version of digest.db is intended to be polished with input from its users. While major flaws and inconsistencies in the data were captured during the pre-processing stage, it is expected that typographical errors and some inconsistencies remain. Please leave a comment or send an email, if you spot an error. A reporting tool or a collaborative editing method will de added in due course.
The database is also intended to be enriched with additional features in its tables and additional tables including new perspectives about the textual data. One possible expansion is a high-level taxonomy of legal concepts projected onto the textual units and thematic sections which will assist topical research of Roman law.
Currently there is no custom-made GUI for using digest.db. As the project and the database matures, an appropriate user-friendly interface and visualisation tool will be created to open up the database to those less familiar with the SQL query language.
Footnotes
1See the method of arriving at these dates under Jurist dataframes in the Ddf documentation.