diff --git a/NLP_documetation.md b/NLP_documetation.md
index 738c88d28068f6b013d7e68a93f476e73295d7e1..9f3bcfe3207b1d35e246c01a95d3ed57f77b7ed5 100644
--- a/NLP_documetation.md
+++ b/NLP_documetation.md
@@ -20,7 +20,7 @@ The constructed stoplist is imported as `D_stoplist_001.txt` with `cum2` (prepos
`NLP_sections_001.py > D_lemmatized.csv, tfidf_sections.csv, tfidf_titles.csv`
-The script loads loads the necessary packages including pandas, regex, nmupy and cltk's `BackoffLatinLemmatizer`. It initilizes the lemmatizer with cltk's Latin model.
+The script loads loads the necessary packages including pandas, regex, numpy and cltk's `BackoffLatinLemmatizer`. It initilizes the lemmatizer with cltk's Latin model.
The `TfidfVectorizer` function is imported from sckit-learn. The function calculates "Term frequency-inverse document frequency" (Tfidf) scores for terms in a document (`doc`) where the document forms part of a collection of documents (`corpus`). The score indicates the term's importance in a `doc` relative to the term's importance in the `corpus`. The Tfidf score is calculated as the dot product of term t's _Term frequency_ (Tf) and its logarithmically scaled _Inverse document frequency_ (Idf) where (1) Tf is the number of times term t appears in a document divided by the total number of terms in the document and where (2) Idf is the natural logarithm of the total number of documents divided by the number of documents with term t in it.
@@ -32,7 +32,7 @@ The title and text of thematic sections are passed to `TfidfVectorizer` as two c
`NLP_sections_002.py > D_lemmatized_norm.csv, tfidf_sections_norm_top50.csv, tfidf_titles_norm.csv`
-The script losds the dataframes created in the previous step and normalizes them by removing outliers and reducing dimensions.
+The script loads the dataframes created in the previous step and normalizes them by removing outliers and reducing dimensions.
The thematic sections are sorted by the number of unique lemmas. The average number of unique lemmas is 347.34, the median is 270. The percentile test shows that approximately 21.5% of thematic sections have less than 100 unique lemmas. These thematic sections are too short and they are likely to distort clustering and other NLP analysis. These 93 sections are removed from the normalized dataframes.
diff --git a/README.md b/README.md
index c55d814088a4c91526f7ab83364020293b1eebcd..c4d611257e245f12765c356889f1d39724ebbc27 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,10 @@
# pyDigest - Roman Law in machine-readable format
-[introductory paragraph]
+The _Digest_ is the definitive Roman law compendium compiled under emperor Justinian I (533 CE). The project applies computational methods to the _Digest_ text to get deep insights about Roman law which would supplement and guide close reading research.
+
+The research is carried out at the University of Surrey School of Law as part of an Early Career Research Fellowship funded by The Leverhulme Trust (ECF-2019-418). The project's current public [GitLab repository](https://gitlab.eps.surrey.ac.uk/mr0048/pydigest) includes scripts and files accompanied by detailed documentation.
+
+<img src="/images/Leverhulme_Trust_RGB_blue.png" height="120"> <img src="/images/Surrey_SoL_logo.jpg" height="160"> <img src="/images/gitlab-logo-gray-rgb.png" height="120">
## Project components
diff --git a/SQL_documentation.md b/SQL_documentation.md
index 28cb34c30353eee70397461d27a0d98bb59da417..fd005d618e0ced2e775baef7bfa09e3e31f5d78e 100644
--- a/SQL_documentation.md
+++ b/SQL_documentation.md
@@ -1,8 +1,10 @@
## "SQL" - Relational database
-SQLite database built with `sqlite3` on the command line and the `sqlite3` Python package.
+This relational database presents the _Digest_ in interlinked data tables chained together by unique keys. The `digest.db` database can be used for generating advanced analytical insights about Roman law as represented by the _Digest_ and for searching text and associated data in a structured and efficient manner.
-### 1. Create database: digest.db
+The SQLite database was built with `sqlite3` on the command line and the `sqlite3` Python package.
+
+### 1. Create database: `digest.db`
1. `D_sql_create_db.py > digest_skeleton.db`
@@ -12,7 +14,9 @@ The Python script imports `sqlite3` and its `Error` function and creates an empt
The core structure of the `digest` database is drafted in the yEd graph editor and stored in the `images` folder of the repository. It includes the name and datatype of the fields in the various tables and notes their primary (PK) and foreign keys (FK). The graph's edges uses the arrow symbols to indicate one-and-only-one to many-or-one relations between the tables.
-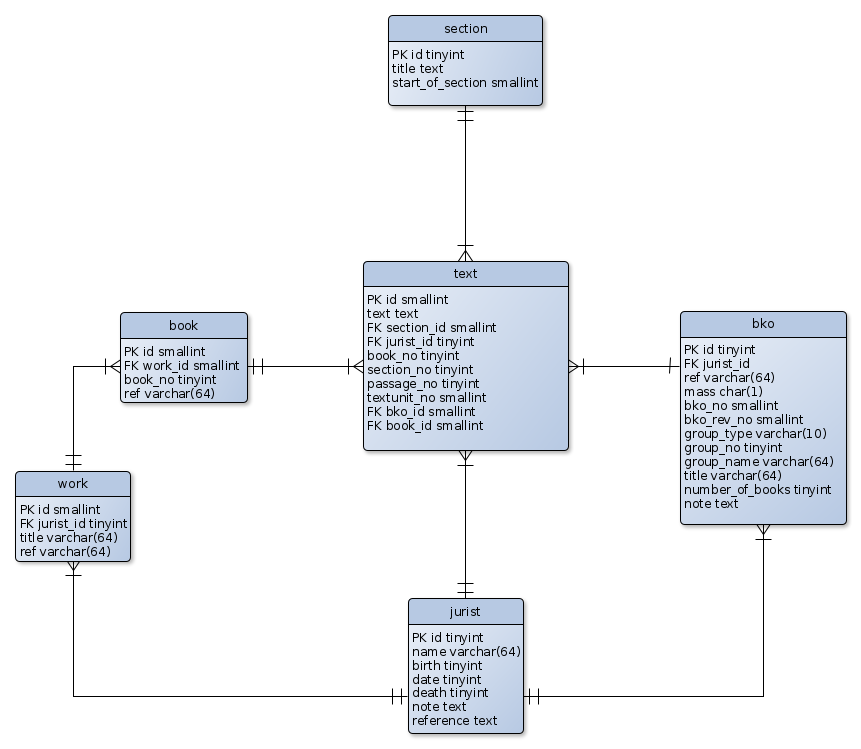
+The graph below is a visual representation of the tables in the database. Each table includes an "id" as primary key (PK) and one or more foreign keys (FK) which point to the "id" columnn of a different table. It is by foreign keys that the tables are chained together in many-to-one relationships. The entity boxes for the tables include the names and datatypes of the columns where "tinyint" and "smallint" are two types of integer, "varchar" is a limited length, while "text" is an unlimited length text type. The three colours indicate the three different sources from which the tables are created. Tables in shaded blue are created from the same source as the core "text" table, i.e. the _Digest_ text as presented in Amanuensis, but they were separated to structure the information.
+
+
3. `D_sql_create_tables.py > digest_skeleton.db`
@@ -22,65 +26,8 @@ Running the file creates the tables which are checked by looking at `digest.db`
4. `D_sql_load_data.py > digest.db`
-A copy of `digest_skeleton.db` is made in the same directory. This `digest.db` file will be used to populate the database with information from the flat files created in the ["Ddf"](https://github.com/mribary/pyDigest/blob/master/Ddf_documentation.md) stage of the project. The script establishes a connection with the database by creating a `Connection` object. Six `create_` functions are defined for each of the six empty tables in `digest.db`: (1) `create_jurist`, (2) `create_work`, (3) `create_book`, (4) `create_bko`, (5) `create_section`, and (6) `create_text`. These functions create a `Cursor` object with a method of the `Connection` object and include a `SQL` statement which enters one row into the table with values matching the table's column labels. As the struture of flat files do not match the structure of the tables, the script creates some temporary dataframes collecting information in the right order, right format and adhering to the restrictions (keys, data types restrictions etc.) of the `SQL` schema. The script's main function populates the tables with the `create_` functions by looping over the rows in the relevant flat files. The script ends with the command of running the `main` function. No error message is received which means that the loaded data adheres to the restrictions. The populated `digest.db` database file is inspected with the `sqlite3` command line application as well as in the graphical interface of `DB Browser for SQLite`.
+A copy of `digest_skeleton.db` is made in the same directory. This `digest.db` file will be used to populate the database with information from the flat files created in the ["Ddf"](/Ddf_documentation.md) stage of the project. The script establishes a connection with the database by creating a `Connection` object. Six `create_` functions are defined for each of the six empty tables in `digest.db`: (1) `create_jurist`, (2) `create_work`, (3) `create_book`, (4) `create_bko`, (5) `create_section`, and (6) `create_text`. These functions create a `Cursor` object with a method of the `Connection` object and include a `SQL` statement which enters one row into the table with values matching the table's column labels. As the struture of flat files do not match the structure of the tables, the script creates some temporary dataframes collecting information in the right order, right format and adhering to the restrictions (keys, data types restrictions etc.) of the `SQL` schema. The script's main function populates the tables with the `create_` functions by looping over the rows in the relevant flat files. The script ends with the command of running the `main` function. No error message is received which means that the loaded data adheres to the restrictions. The populated `digest.db` database file is inspected with the `sqlite3` command line application as well as in the graphical interface of `DB Browser for SQLite`.
### 2. Instructions for using `digest.db`
-The `digest.db` database can be used for generating advanced analytical insights about Roman law as represented by the _Digest_. The database can be queried with standard `SQL` statements in three types of `SQLite` interfaces listed below.
-
-1. `Command line interface (CLI) - sqlite3`
-
-Instructions for installation can be accessed on [sqlite.org](https://www.sqlite.org/download.html).
-
-2. `Graphical user interface (GUI) - DB Browser for SQLite`
-
-Instructions for installation and use can be accessed on [sqlitebrowser.org](https://sqlitebrowser.org/dl/).
-
-3. `Online application - SQLite online`
-
-Instructions for installation and use can be accessed on [sqliteonline.com](https://sqliteonline.com/).
-
-The websites of the listed applications include instructions for querying databases with `SQL` statements. All interfaces allow exporting results into flat files such as `csv`. The exported `csv` could be opened in a regular spreadsheet application such as Excel or libreoffice-calc. The `csv` files could also be loaded as `pandas` dataframes into a Python code for further processing.
-
-### 3. Sample SQL queries
-
-There are some sample queries in the `SQL_queries.txt` file to assist users unfamiliar with the `SQL` query language. The queries are all ready to be copied and pasted as a multi-line `SQL` query into the interface of your choice. The queries can be customised by replacing the relevant values. Names of tables and their columns are fixed, but all other values can be customised. Please play around.
-
-Take the following `SQL` query from `SQL_queries.txt`.
-
-```sql
--- Count the number of text units for each jurists
-SELECT j.name, j.date,
- COUNT(t.jurist_id) as number_of_textunits,
- CASE
- WHEN j.date < 0 THEN 'E'
- WHEN j.date < 190 THEN 'C-'
- WHEN j.date < 240 THEN 'C+'
- ELSE 'P'
- END AS era
-FROM text as t
-LEFT JOIN jurist as j
-ON t.jurist_id=j.id
-GROUP BY t.jurist_id
-ORDER BY j.date;
-```
-
-This query sorts the jurists of the _Digest_ into so-called eras: "early and pre-classical" ('E'), "early classical" ('C-'), "late classical" ('C+'), and "post-classical" ('P'). The `date` column in the `jurist` table includes the date when the jurist was most active.[<sup id="inline1">1</sup>](#fn1) For the purpose of this periodisation, the query takes the year 0, the year 190 and the year 240 as the boundaries of the eras. Additionally, the query counts the number of text units authored by a partcular jurists by linking the `jurist` and the `text` table on a common key (`jurist_id`). The output is ordered by date where jurists, their eras and the number of text units they have in the _Digest_ are listed in `SQL` table ready to be exported.
-
-The user may define different boundaries, or name the eras differently by replacing the numeric values and the encoding of eras stated in single quotation marks. Less or more eras can be defined by removing a `WHEN` line or adding more to the query as appropriate.
-
-#### Help with SQL queries
-
-Please leave a comment or send an [email](mailto:m.ribary@surrey.ac.uk), if you would like to request a sample `SQL` query for your research, or if you need help adusting one of the existing queries.
-
-### 4. Future steps
-
-The current version of `digest.db` is intended to be polished with input from its users. While major flaws and inconsistencies in the data were captured during the pre-processing stage, it is expected that typographical errors and some inconsistencies remain. Please leave a comment or send an [email](mailto:m.ribary@surrey.ac.uk), if you spot an error. A reporting tool or a collaborative editing method will de added in due course.
-
-The database is also intended to be enriched with additional features in its tables and additional tables including new perspectives about the textual data. One possible expansion is a high-level taxonomy of legal concepts projected onto the textual units and thematic sections which will assist topical research of Roman law.
-
-Currently there is no custom-made GUI for using `digest.db`. As the project and the database matures, an appropriate user-friendly interface and visualisation tool will be created to open up the database to those less familiar with the `SQL` query language.
-
-### Footnotes
-
-[<sup id="fn1">1</sup>](#inline1)See the method of arriving at these dates under [Jurist dataframes](https://github.com/mribary/pyDigest/blob/master/Ddf_documentation.md#3-additional-dataframes) in the Ddf documentation.
\ No newline at end of file
+Further information and instructions for use are included in the [`README.md` file in the `sql` folder](/sql/README.md).
\ No newline at end of file